0
留言稍后联系!

本文摘要:摘要:在线知识蒸馏通过同时训练两个或多个模型的集合,并使之相互学习彼此的提取特征,从而实现模型性能的共同提高。已有方法侧重于模型间特征的直接对齐,从而忽略了决策边界特征的独特性和鲁棒性。该算法利用一致性正则化来指导模型学习决策边界的判别性
摘要:在线知识蒸馏通过同时训练两个或多个模型的集合,并使之相互学习彼此的提取特征,从而实现模型性能的共同提高。已有方法侧重于模型间特征的直接对齐,从而忽略了决策边界特征的独特性和鲁棒性。该算法利用一致性正则化来指导模型学习决策边界的判别性特征。具体地说,网络中每个模型由特征提取器和一对任务特定的分类器组成,通过正则化同一模型不同分类器间以及不同模型对应分类器间的分布距离来度量模型内和模型间的一致性,这两类一致性共同用于更新特征提取器和决策边界的特征。此外,模型内一致性将作为自适应权重,与每个模型的平均输出加权生成集成预测值,进而指导所有分类器与之相互学习。在多个公共数据集上,该算法均取得了较好的表现性能。
关键词:计算机视觉;模型压缩;在线知识蒸馏;一致性正则化
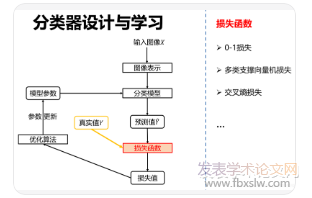
引言深度神经网络(Deepneuralnetworks,DNNs)在目标检测与追踪[1,2]、语义分割[3,4]、图像分类[5,6]等多种计算机视觉任务中均取得了显著的研究成果。然而,性能优越的DNN模型往往依赖于较深的网络结构和较大的计算量,因此极大地限制了其在存储空间有限的设备中的广泛应用。近年来,研究者们对模型压缩方法进行了广泛的探索与研究,主要可以分为以下四大类:a)模型剪枝[7,8],b)网络量化[9,10],c)直接搭建紧凑的网络模型[11,12],d)知识蒸馏(KnowledgeDistillation,KD)[13,26,27,28]。其中,KD又可以分为离线知识蒸馏(offlineKD)和在线知识蒸馏(onlineKD)两大类。
传统的offlineKD方法分两阶段进行,首先需要预训练一个性能较强的大网络模型,这一过程会造成计算成本的额外消耗,然后冻结其参数并进一步指导小模型来学习拟合该大模型的输出预测分布或中间层特征等知识信息,从而实现小模型的性能提高。为了克服offlineKD分步训练的缺点和局限性,研究者们近些年提出了onlineKD的思想,即无须大模型的预训练过程,而是在目标任务的监督下,以协作的方式同时训练所有对等网络模型并指导它们相互学习彼此之间的预测分布和特征知识,从而实现对等模型性能的共同提高。
其中,最具代表性的深度相互学习网络(DML)[13]即是通过指导对等模型直接学习其他模型的最终预测分布从而实现了在线知识蒸馏与迁移;动态集成网络(ONE)[14]则是引入了一个门控单元来指导对等模型之间的相互学习;特征融合学习网络(FFL)[15]提出了融合分类器从而实现与对等模型之间的相互知识学习;Chen等人[16]提出的OKKDip网络使用两级蒸馏训练实现了多个辅助模型与一个主模型之间的相互学习;Guo等人提出的KDCL[17]通过整合较小模型的输出预测和增强后的输入图像从而生成软化目标作为监督信息,进一步提高模型的性能。尽管这些onlineKD算法已经取得了较好的实验结果,但它们在每个模型中均采用单个分类器来输出预测分布,更重要的是,已有方法忽略了决策边界周围的模糊特征。
为了克服该缺点,本文基于一致性正则化设计了一个在线知识蒸馏网络(OKDCR),实现了两个或多个对等模型之间模糊特征的识别与对齐,从而进一步提高了模型的表现能力。对于每个对等模型,OKDCR引入了一对任务特定的分类器,并使之共享同一个的特征提取器。给定一个输入图像,将其自由变换两次后输入给各个模型的特征提取器,从而为每个模型中的不同分类器生成不同的特征。
通过衡量每个模型的两个分类器之间以及跨模型的对应分类器之间预测值分布的一致性,即模型内一致性和模型间一致性,以此来更新特征提取器的参数,增强其对模糊特征识别的鲁棒性。此外,模型内一致性用来计算自适应权重,并与每个模型的平均输出共同生成最终的集成预测值,进一步为所有分类器提供额外的监督信息。大量实验结果表明,OKDCR训练的对等网络模型在一致性正则化以及自适应集成预测的指导与监督下,能够学习到具有更强识别能力的特征,其表现性能和实验结果始终优于已有的最新水平。这项工作的贡献可以概括为以下三个方面:
1)设计了一个新的网络架构OKDCR,引入模型内一致性和模型间一致性来规范两个或多个对等模型内和跨模型间的在线协作学习,提高特征提取器的鲁棒性。2)其次,根据模型内一致性设计了一个自适应集成预测方案,为对等模型之间的在线知识蒸馏产生额外的监督信息,提高分类器的辨别性和稳定性。3)大量的实验证明了本文提出的一致性正则化算法的有效性,即OKDCR与现有的onlineKD方法相比,取得了更好的分类结果和表现性能。
OKDCR在用于研究知识蒸馏的三个公开公共数据集上进行了性能评估与分析。其中,CIFAR10[18]和CIFAR100[19]是应用广泛的图像分类数据集,它们分别有10个和100个图像类别,各自均有50000个训练图像和10000个测试图像,两个数据集中的所有图像都是由32×32像素的RGB颜色构成。
对于图像增强与变换,实验部分采用与现有的onlineKD方法[14,20]中相同的操作,即用零将原始输入填充为40×40图像并随机裁剪出32×32区域。第三个数据集ImageNet[21]是由120万个训练图像和50000个验证图像组成,共有1000个图像类别。为了与已有方法进行公平的比较,对于图像变换,实验部分采用与[14]相同的操作,即水平翻转并随机裁剪出224×224区域。在实验结果评估中分别使用Top-1/Top-5平均分类准确率(%),其中前者用于CIFAR10/CIFAR100/ImageNet数据集,而后者仅用于ImageNet数据集。
所有实验都是在NVIDIAGPU设备上基于PyTorch实现的。在训练过程中,采用带Nesterov动量的随机梯度下降法进行优化,动量衰减和权重衰减分别设置为0.9和10-4。在CIFAR10和CIFAR100数据集上,总训练次数和批量大小分别设置为300和128,对等网络的学习率在训练次数的50%时从0.1下降到0.01,在75%时下降到0.001。在ImageNet数据集上,采用128的最小批量大小,学习速率从0.1开始,每30个训练周期衰减0.1倍,总共90个周期。
在CIFAR10和CIFAR100&ImageNet上,式(2)中的平衡参数和分别设置为1和100。与对比方法[22,23]相同,式(3)中的温度参数T在整个实验过程中设置为3从而进行公平的比较。为了促使模型更加稳定和高效的学习,式(6)中的加权因子根据训练步骤按照min(1,1.25(s/S))进行更新的,其中s和S是分别表示当前训练次数和总训练次数。
实验部分将OKDCR与DualNe[20]、DML[13]、ONE[14]、FFL[15]、AMLN[24]、KDCL[17]、OKKDip[16]等多种onlineKD方法进行了对比。在以下的实验对比结果表格中,“Avg”和“Ens”分别表示模型1(Net1)和模型2(Net2)的平均分类准确率和集成分类准确率,“vanilla”下的“1C”和“2C”是指模型分别采用一个分类器和两个分类器并只在交叉熵分类损失函数监督下的单独训练结果。
显示了在CIFAR10和CIFAR100上使用相同对等网络模型结构时的最高Top-1分类准确率。在对比的方法中,DML和AMLN致力于提高单个模型的性能,而DualNet的目标是提高集成预测的分类结果。从实验结果可以观察到,DML、DualNet、ONE、FFL、AMLN和OKDCR表现性能均优于vanilla基准网络。
其中,ONE和FFL在CIFAR10和CIFAR100上的分类准确率相似,而本文所提出的OKDCR在“Avg”和“Ens.”上取得了最高的分类结果。从模型的平均准确率“Avg”来看,ONE、FFL、AMLN和OKDCR在四组网络模型中均优于DML,在CIFAR10上分别提高了0.87%、1.11%、2.44%和3.40%,在CIFAR100上分别提高了6.56%、4.82%、9.11%和10.22%;从集成准确率“Ens.”来看,ONE、FFL和OKDCR在CIFAR10上比DualNet分别提高了0.32%、0.53%和4.60%,而在CIFAR100分别提高了2.31%、3.61%和10.94%。
此外,不同方法在CIFAR10上的测试精度变化过程进行了可视化,从中可看出,在学习率变化的训练节点,各个方法的准确率均发生明显的提高,且OKDCR训练的单个模型其性能始终优于已有的对比方法,表现出相对稳定性和一致性。为了验证该方法是否具有通用性,OKDCR接着在CIFAR10和CIFAR100上使用不同的对等网络模型对(WRN16-2&ResNet32,WRN-40-2&ResNet56)进行了评估。
Net1&Net2使用OKDCR方法训练时,其性能始终优于其他在线蒸馏方法。以在CIFAR100数据集上WRN-16-2&ResNet32的分类结果为例,OKDCR训练的Net1&Net2比DML、FFL和AMLN训练的Net1&Net2分别高出2.54%&3.29%、2.02%&2.04%和0.21%&0.33%。OKDCR的优异性能主要归功于两个因素:首先,模型内和模型间的一致性正则化有助于模型更好地学习决策边界附近的特征对齐;其次,自适应集成预测能够为模型提供良好的监督,并指导对等网络学习更多的辨别性特征知识。
图像论文范例: 通过风格迁移的浓雾天气条件下无人机图像目标检测方法
本文提出了一种基于一致性正则化的在线知识蒸馏方法(OKDCR),与现有的工作不同,OKDCR在每个模型中引入一个共享的特征提取器和两个任务特定的分类器。基于每个模型内分类器间以及不同模型对应分类器间的分布差异,从而对模型内一致性和模型间一致性进行正则化,并用于特征提取器的参数更新,增强其对模糊特征的提取能力和鲁棒性。此外,利用模型内一致性生成自适应权值,并作为每个模型平均预测的权重,从而生成对等模型的最终集成预测,进一步对所有分类器提供额外的监督信息,提高其对模糊特征的辨别能力。
实验部分在三个具有挑战性的图像分类数据集上进行了广泛的评估与分析,与现有最新的在线知识蒸馏方法相比,OKDCR表现出明显的优越性和有效性。在未来的工作中,会进一步探究多个分类器共享特征提取器的模型性能表现,以及不同分类器使用不同任务训练且彼此相互学习时的表现效果。
参考文献:
[1]PérezgonzálezA,VergaraM,SanchobruJL,etal.Visualizingdatausingt-sne[J].JournalofMachineLearningResearch,2015.
[2]WangJiang,YangYi,MaoJunhua,etal.CNN-RNN:Aunifiedframeworkformulti-labelimageclassification[C]//InIEEEConferenceonComputerVisionandPatternRecognition,2016:2285-2294.
[3]ParkSB,LeeJW,SangKK.Content-basedimageclassificationusinganeuralnetwork-ScienceDirect[J].PatternRecognitionLetters,2004,25(3):287-300.
[4]LiuWei,AnguelovD,ErhanD,etal.SSD:Singleshotmultiboxdetector[C]//InEuropeanConferenceonComputerVision,2016:21-37.
[5]BelagiannisV,FarshadA,GalassoF.Adversarialnetworkcompression[C]//InEuropeanConferenceonComputerVision,2018:431-449.
[6]LiuPeiye,LiuWu,MaHuadong,etal.KTAN:Knowledgetransferadversarialnetwork[C]\arXivpreprintarXiv:1810.08126,2018.
[7]LuoJianhao,WuJianxin,LinWeiyao.ThiNet:Afilterlevelpruningmethodfordeepneuralnetworkcompression[C]//InIEEEInternationalConferenceonComputerVision,2017:5058–5066.
[8]MolchanovP,TyreeS,KarrasT,etal.Pruningconvolutionalneuralnetworksforresourceefficienttransferlearning[C]//arXivpreprintarXiv:1611.06440,2016.
[9]CourbariauxM,HubaraI,SoudryD,etal.Binarizedneuralnetworks:Trainingdeepneuralnetworkswithweightsandactivationsconstrainedto+1or-1[C]//arXivpreprintarXiv:1602.02830,2016.
作者:张晓冰,龚海刚,刘明

转载请注明来自发表学术论文网:http://www.fbxslw.com/dzlw/27974.html

2023-2024JCR影响因子

SCI 论文选刊、投稿、修回全指南

SSCI社会科学期刊投稿资讯

中外文核心期刊介绍与投稿指南

sci和ssci双收录期刊

EI收录的中国期刊

各学科ssci

各学科sci

各学科ahci

EI期刊CPXSourceList

历届cssci核心期刊汇总

历届cscd-中国科学引文数据库来源期刊

CSCD(2023-2024)

中科院分区表2023

中国科技核心期刊历届目录

2023年版中国科技核心期刊目录(自然科学)

2023年版中国科技核心期刊目录(社会科学)

历届北大核心

2023版第十版中文核心目录
2023-2024JCR影响因子
SCI 论文选刊、投稿、修回全指南
SSCI社会科学期刊投稿资讯
中外文核心期刊介绍与投稿指南
sci和ssci双收录期刊
EI收录的中国期刊
各学科ssci
各学科sci
各学科ahci
EI期刊CPXSourceList
历届cssci核心期刊汇总
历届cscd-中国科学引文数据库来源期刊
CSCD(2023-2024)
中科院分区表2023
中国科技核心期刊历届目录
2023年版中国科技核心期刊目录(自然科学)
2023年版中国科技核心期刊目录(社会科学)
历届北大核心
2023版第十版中文核心目录

请填写信息,出书/专利/国内外/中英文/全学科期刊推荐与发表指导


